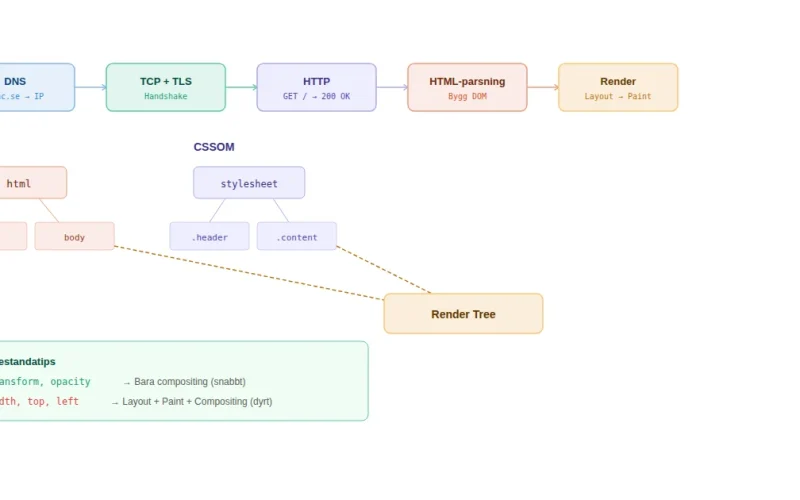
Hur fungerar en webbläsare – från URL till färdig sida
- Steg 1: DNS — hitta serverns adress
- Steg 2: Anslutning — TCP och TLS
- Steg 3: HTTP-förfrågan och svar
- Steg 4: HTML-parsning och DOM-konstruktion
- Steg 5: CSSOM — webbläsarens stilberäkning
- Steg 6: Render tree, layout och paint
- Varför det spelar roll för prestanda
- Webbläsarens utvecklingsverktyg
- Sammanfattning
Du skriver en adress i webbläsaren, trycker Enter, och en sekund senare har du en komplett webbsida framför dig. Men under den sekunden händer det enormt mycket — DNS-uppslag, TCP-anslutningar, HTTP-förfrågningar, HTML-parsning, CSS-beräkning, layout, rendering och målning av pixlar på skärmen.
Att förstå vad webbläsaren faktiskt gör är inte bara akademiskt intressant — det gör dig till en bättre webbutvecklare. Här går vi igenom hela kedjan, från URL till färdig sida.
Steg 1: DNS — hitta serverns adress
När du skriver monc.se i adressfältet behöver webbläsaren först ta reda på vilken IP-adress som hör till domännamnet. Det sker via DNS (Domain Name System), som fungerar som internets telefonkatalog.
Webbläsaren kollar först sin egen cache — har du besökt sidan nyligen finns svaret redan. Därefter frågar operativsystemets cache, sedan din routers cache, och slutligen din internetleverantörs DNS-server. Om ingen har svaret skickas frågan vidare uppåt i DNS-hierarkin tills rätt IP-adress hittas.
Det här steget tar vanligtvis 20–120 millisekunder. Verktyg som dns-prefetch i HTML låter webbläsaren göra DNS-uppslag i förväg för domäner du vet att sidan kommer att behöva, till exempel CDN:er och tredjeparts-API:er.
Steg 2: Anslutning — TCP och TLS
Med IP-adressen i hand upprättar webbläsaren en TCP-anslutning med servern. Det sker via en ”three-way handshake” — tre meddelanden som bekräftar att båda sidor är redo att kommunicera.
Använder sidan HTTPS (vilket i princip alla gör idag) följer en TLS-handshake ovanpå TCP:n. Webbläsaren och servern förhandlar om krypteringsalgoritm, utbyter nycklar och verifierar serverns SSL-certifikat. Först därefter kan data skickas säkert.
HTTP/2 och HTTP/3 har optimerat den här processen avsevärt. HTTP/2 multiplexar flera förfrågningar över en enda anslutning, och HTTP/3 använder QUIC-protokollet som bygger på UDP istället för TCP, vilket minskar antalet roundtrips som krävs.
Steg 3: HTTP-förfrågan och svar
Webbläsaren skickar en HTTP GET-förfrågan till servern med information om vilken resurs den vill ha, vilken webbläsare som frågar och vilka format den accepterar. Servern svarar med en statuskod (200 OK om allt gick bra), HTTP-headers med metadata, och själva HTML-dokumentet.
Headers innehåller viktig information: Content-Type som talar om att svaret är HTML, Cache-Control som styr hur länge resursen får cachas, och Content-Encoding som anger eventuell komprimering (vanligtvis gzip eller Brotli).
Caching spelar en stor roll för prestanda. Om webbläsaren redan har en cachad version av resursen och servern bekräftar att den inte ändrats (via 304 Not Modified) behöver hela dokumentet inte laddas ner igen. Det är därför en sida ofta laddar betydligt snabbare vid andra besöket — DNS, anslutning och resurser finns redan i cache.
Steg 4: HTML-parsning och DOM-konstruktion
Nu börjar det intressanta. Webbläsaren tar emot HTML-dokumentet som en ström av bytes och börjar parsa det — tecken för tecken, tagg för tagg — till ett DOM-träd (Document Object Model).
DOM:en är en trädstruktur där varje HTML-element blir en nod. <html> är roten, <head> och <body> är barn, och alla element däri grenar vidare neråt. Det är den strukturen som JavaScript sedan interagerar med via metoder som document.querySelector().
Parsningen är inte helt rak. När webbläsaren stöter på en <script>-tagg pausar den HTML-parsningen, laddar ner scriptet och kör det — det kan ju modifiera DOM:en som håller på att byggas. Det är därför <script>-taggar traditionellt placeras precis före </body>, och varför defer-attributet finns: det låter scriptet laddas parallellt men väntar med exekveringen tills HTML:en är färdigparsad.
<link>-taggar till CSS-filer blockerar inte HTML-parsningen men blockerar renderingen — webbläsaren vägrar visa sidan förrän den vet hur den ska se ut. Det kallas render-blocking, och det är anledningen till att stora, ooptimerade CSS-filer kan fördröja den första visuella rendringen avsevärt.
Moderna webbläsare har en ”preload scanner” som tittar framåt i HTML:en medan parsern är blockerad, och börjar ladda resurser den vet kommer att behövas — CSS-filer, bilder och scripts. Det är en optimering som sker automatiskt och gör stor skillnad i praktiken.
Steg 5: CSSOM — webbläsarens stilberäkning
Parallellt med DOM-konstruktionen bygger webbläsaren ett CSSOM (CSS Object Model) från alla stilmallar. Varje CSS-regel parsas, specificitet beräknas, och arv appliceras. Resultatet är en fullständig stilbeskrivning för varje element i DOM:en.
Det är i det här steget som CSS cascading, specificitet och arv spelar ut — webbläsaren avgör vilka regler som gäller för varje element baserat på de principer vi beskrivit i andra artiklar.
Steg 6: Render tree, layout och paint
Med DOM:en och CSSOM på plats kombinerar webbläsaren dem till ett render tree — en träd-struktur som bara innehåller synliga element med deras beräknade stilar. Element med display: none finns i DOM:en men inte i render tree.
Layout-steget (ibland kallat ”reflow”) beräknar varje elements exakta position och storlek på skärmen. Det är här som CSS-värden som width: 50%, margin: auto och flex: 1 omvandlas till konkreta pixelvärden.
Paint-steget konverterar render tree till faktiska pixlar. Webbläsaren ritar text, färger, bilder, ramar och skuggor för varje element. Och slutligen, i compositing-steget, läggs alla lager ihop till den slutliga bilden som visas på skärmen.
Varför det spelar roll för prestanda
Varje förändring du gör på sidan triggar potentiellt delar av den här kedjan igen. Ändrar du en elements width i JavaScript triggar det layout (reflow), paint och compositing. Ändrar du color triggar det paint och compositing men inte layout. Ändrar du transform eller opacity triggar det bara compositing — det billigaste steget.
Det är därför CSS-animationer med transform och opacity är så mycket snabbare än animationer med top, left, width eller height. De sista fyra triggar layout-omberäkning för varje animationsframe, medan de första två hanteras helt av GPU:n.
Några praktiska konsekvenser: undvik att ändra layout-triggande egenskaper i animationer. Använd will-change: transform för att hinta till webbläsaren att ett element kommer att animeras. Och batchera DOM-ändringar istället för att göra dem en åt gången — varje enskild ändring kan trigga en ny layout-beräkning.
Webbläsarens utvecklingsverktyg
Chrome DevTools Performance-panelen visualiserar hela render-pipelinen. Du kan se exakt hur lång tid varje steg tar — parsning, stilberäkning, layout, paint, compositing — och identifiera flaskhalsar. Network-panelen visar DNS-uppslag, anslutningar och varje enskild resurs som laddas, med timing för varje fas.
Det är en av de mest kraftfulla resurserna du har som webbutvecklare, och det är gratis.
Sammanfattning
En webbläsare gör enormt mycket arbete på under en sekund. DNS löser domännamnet till en IP-adress. TCP och TLS upprättar en säker anslutning. HTTP hämtar HTML-dokumentet. Parsern bygger DOM och CSSOM. Render tree, layout och paint producerar de pixlar du ser. Och varje förändring du gör med JavaScript eller CSS triggar delar av kedjan igen — det är därför prestanda-medveten utveckling handlar om att förstå vilka steg som triggas och minimera onödigt arbete.